

 如果结果不匹配,请
如果结果不匹配,请 
 更多“在一个长度为n的循环链表中,删除其元素值为x的结点的时间复杂…”相关的问题
更多“在一个长度为n的循环链表中,删除其元素值为x的结点的时间复杂…”相关的问题
A.在单链表第一个元素前插入一个新元素
B.在单链表最后一个元素后插入一个新元素
C.删除单链表中的第一个元素
D.删除单链表中的最后一个元素
A.删除所有值为x的元素
B.在最后一个元素的后面插入一个新元素
C.顺序输出前k个元素
D.交换第i个元素和第n-i-1个元素的值(i=1,1,n)
A、错误
B、正确
A.正确
B.错误
A.非循环双链表
B.循环双链表
C.只有表尾指针没有表头指针的循环单链表
D.只有表头指针没有表尾指针的循环单链表
请根据下面介绍的跳跃表的思想实现跳跃表。
为了提高链表的检索效率,可以参考顺序表把单链表中元素排序,然后采用类似二分法的思想进行折半检索。不过,因为链表中结点的位置不是连续存放的,所以为了折半检索的需要,把单链表扩充为多链结构,借助于一些支持折半的“跳跃的指针”,把检索的范围快速缩小。
下图(a)是一个简单的链表,其结点按照结点值的顺序排列,检索排序的链表需要沿着链表一个结点一个结点的移动,平均需要访问n/2个结点。考虑添加一个指向其他后继结点的指针,以便交替地跳过结点的直接后继结点,如下图(b)所示。把只有1个指针的结点定义为0级跳跃表结点,把有2个指针的结点定义为1级跳跃表结点。进行检索时,先沿着1级指针走,直到找到一个后继比检索关键码大的值。然后回到0级指针,如果需要的话,再多走一个结点,这样可有效地把工作量减半。类似地,可以继续以这种方式添加指针,直到像下图(c)那样,对于一个有n=8个结点的表,只要有log2n=3个指针。进行检索时,第一步就可以跳过n/2个结点,然后根据需要使得步伐越来越短(类似二分法检索)。通过这种安排,平均情况下的访问数是O(log2n)。

下图(c)是一个理想的跳跃表。其中一半的结点只有1个指针,四分之一的结点有2个指针,八分之一的结点有3个指针,依此类推。而且同一级的指针跳跃的跨度是相同的。这是一个完全“等跨度”的跳跃表。
概率数据结构的思想
跳跃表与有序的顺序表不同,它是一种动态数据结构,它的主要优点是能够动态地保持高效的检索。在频繁执行插入和删除过程维护前面这种“完全”等跨度的代价很大。为了减少维护的代价,仅仅需要维护成随机的等跨度就行。采用的关键技术是按照所谓“概率数据结构”的思想。具体方法如下:
假设元素的插入和删除都是随机的,每当删除一个结点时,在跳跃表中找到该结点后直接删除;关键是在插入一个结点时,要为新结点按概率随机分配一个级别,使得在跳跃表的所有结点中,有一个指针的结点(0级跳跃表结点)概率是50%,有两个指针的结点(1级跳跃表结点)概率是25%……依此类推。这样,根据概率论的观点,进行检索时,平均情况下的访问结点数仍然是O(log2n)。
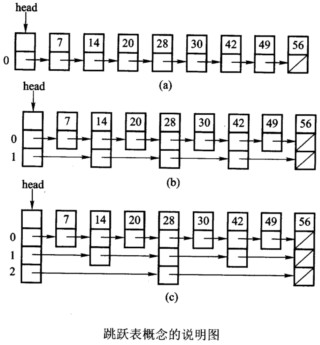 下图(c)是一个理想的跳跃表。其中一半的结点只有1个指针,四分之一的结点有2个指针,八分之一的结点有3个指针,依此类推。而且同一级的指针跳跃的跨度是相同的。这是一个完全“等跨度”的跳跃表。 概率数据结构的思想跳跃表与有序的顺序表不同,它是一种动态数据结构,它的主要优点是能够动态地保持高效的检索。在频繁执行插入和删除过程维护前面这种“完全”等跨度的代价很大。为了减少维护的代价,仅仅需要维护成随机的等跨度就行。采用的关键技术是按照所谓“概率数据结构”的思想。具体方法如下: 假设元素的插入和删除都是随机的,每当删除一个结点时,在跳跃表中找到该结点后直接删除;关键是在插入一个结点时,要为新结点按概率随机分配一个级别,使得在跳跃表的所有结点中,有一个指针的结点(0级跳跃表结点)概率是50%,有两个指针的结点(1级跳跃表结点)概率是25%……依此类推。这样,根据概率论的观点,进行检索时,平均情况下的访问结点数仍然是O(log2n)。
下图(c)是一个理想的跳跃表。其中一半的结点只有1个指针,四分之一的结点有2个指针,八分之一的结点有3个指针,依此类推。而且同一级的指针跳跃的跨度是相同的。这是一个完全“等跨度”的跳跃表。 概率数据结构的思想跳跃表与有序的顺序表不同,它是一种动态数据结构,它的主要优点是能够动态地保持高效的检索。在频繁执行插入和删除过程维护前面这种“完全”等跨度的代价很大。为了减少维护的代价,仅仅需要维护成随机的等跨度就行。采用的关键技术是按照所谓“概率数据结构”的思想。具体方法如下: 假设元素的插入和删除都是随机的,每当删除一个结点时,在跳跃表中找到该结点后直接删除;关键是在插入一个结点时,要为新结点按概率随机分配一个级别,使得在跳跃表的所有结点中,有一个指针的结点(0级跳跃表结点)概率是50%,有两个指针的结点(1级跳跃表结点)概率是25%……依此类推。这样,根据概率论的观点,进行检索时,平均情况下的访问结点数仍然是O(log2n)。
A.关键字是数据元素(或记录)中某个数据项的值,可以标识一个记录,称为主关键字
B.就平均查找长度而言,分块查找最小,折半查找次之,顺序查找最大
C.对长度为n 的有序链表进行对分查找,最坏情况下需要的比较次数为log2n
D.折半查找的先决条件:表中结点按关键字有序,且顺序(一维数组)存储
















